

How can we help?
Search for answers or browse our knowledge base
Data Assembly
Summary
When executing a collection launch action or a restitution launch action, the creation of a document is performed as follows:
For each entity defined by the assignment relationship,
- The server duplicates the template.
- A data set containing all the fields of the address book and all the fields of the assignment relationship is created for the entity concerned: this is the kernel.
- Each compartment of the duplicated document is fed by a dataset resulting from the join between the compartment data source and the diffusion axis.
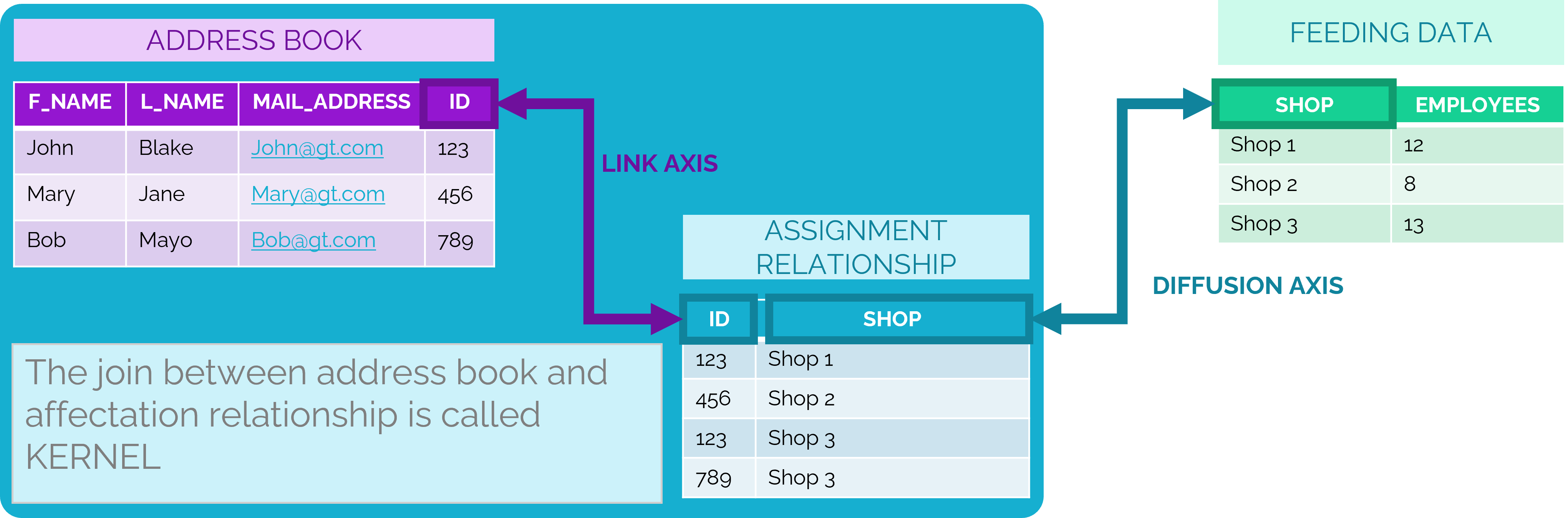
The diffusion axes, therefore, make it possible to filter the data in the compartments. In the example provided by the diagram above, the document of the “Shop 1” entity will receive the value “12” for the “EMPLOYEES” field thanks to the join between the “SHOP” diffusion axis and the “SHOP” field of the feed data. If the diffusion axis had not been “SHOP” but “ID”, then this join would not have been performed and the compartment would have received all the records contained in the feed data.
Building the kernel
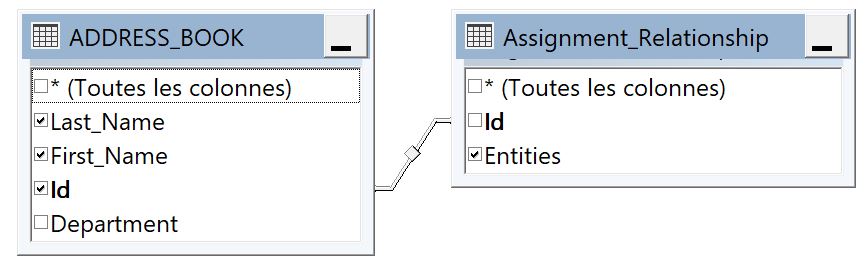
The kernel is the view that collects the data from the address book and the assignment relationship.
The kernel data is produced from an internal join between the address book and the assignment relationship.
The join is performed on the linking axis (this axis must be common to both the address book and the assignment relationship).
All fields of the assignment relationship are embedded in the kernel.
The address book fields that do not exist in the assignment relationship are also embedded in the kernel, it is therfore recommended to ensure only necessary fields are included to avoid performance drop.
The diffusion axes and the axis linking to the address book must be a key to the kernel data.
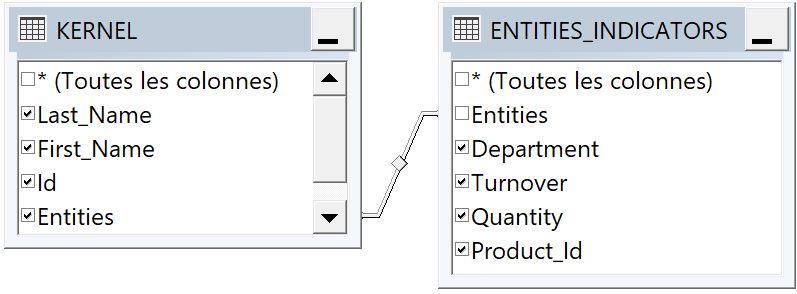
Production of the data blocks associated with each compartment
For each of the corresponding entities (each row in the kernel) :
For each of the tables/views associated with a compartment in the campaign launch action:
A left outer join is performed between the kernel and the compartment table/view.
This join is performed on the common axes between the compartment table/view and the diffusion axes.
All fields of the table that are not already in the kernel (i.e. neither in the address book nor in the assignment relationship) are added to the data block.
If a field exists in the kernel and in the compartment table, the table field will be ignored. If the table field does not have the same meaning as in the kernel and is to be used in the questionnaire, the table field or the kernel field should be renamed (and possibly the components accordingly).
Since an outer join is performed between the kernel and the compartment table, restricting the sending of questionnaires to certain entities cannot be performed on the compartment table, it must be performed on the assignment relationship.
Restricting a compartment table to certain entities will not customise the data for that compartment, but the questionnaire will still be sent.
If none of the diffusion axes exist in the compartment table/view, a Cartesian product is performed between the kernel and the compartment table/view.
In the latter case, if the compartment table/view does not contain any data, only the kernel data is produced; the axes of the compartment table that are not already in the kernel are added with a NULL value.
If the table/view is to be sorted (configured in the launch action), the sorting is performed on the result data block.
Transposition of each data block if necessary
Each previously constructed data block is transposed if the associated compartment refers to a transposition.
The crossings of dimensions expressed by the transposition that do not exist in the questionnaire will simply be ignored during the feeding.
In the case of anonymised dates, this can be an undeniable advantage: the date selection criterion, which may be difficult to express at times, is, in fact, expressed in the questionnaire (only the corresponding anonymised dates will be produced).
In the case of non-anonymised standard axes, it is better to have complete control over the modalities of each of the dimensions (the modalities will probably have to evolve with respect to the questionnaire).
Assembling the blocks produced between them in the questionnaire
The set of data blocks previously constructed for each compartment and a corresponding entity (a row in the kernel) is now injected into the Calame questionnaire.
For each compartment that multiplies cells/sheets during customisation (multi-tab and pattern), a data block (reference block) will determine the set of reference modalities. The other blocks will be assembled with the identified reference blocks.
It is the table/view associated with the highest level compartment that will determine the reference items for the multiplication during customisation.
For example, if a table is associated with the root of the multi-tab, it will determine the reference items.
This means that even if the table of a pattern or transposition in a multi-tab contains more items than the items in the table associated with the root of the multi-tab, the additional items will be ignored.
If two compartments are competing (because they are at the same level) to serve as references for the multi-tab or pattern, the alphabetical order of the compartment names will determine the reference.
Once the reference tables have been chosen for the data of the multi-tabs and patterns, the latter are demultiplied according to the data of these reference tables:
Multi-tabs are scaled-down along the multi-tab axis present in the reference table.
The patterns are scaled-down along as many rows as are present in the reference table.
The data blocks from the other compartments are then added for the key items of the reference block.
In the case of the multi-tab reference block and a block associated with a sub-compartment of the multi-tab, the assembly is performed using the multi-tab axis
In the case of the reference block of a pattern and a block associated with a transposition in this pattern, all fields common to both data blocks are used to make a left outer join (the key items are the items of the reference block that are found in all axes common to both blocks)
If there are two transpositions in the pattern, it is necessary that there is a component in the pattern that is not transposed to serve as a common reference for both transpositions.
This component can be fed completely by one of the two transpositions (the first one in alphabetical order if no block is associated with the pattern).
If an axis exists in the table associated with the parent compartment and in the table associated with the sub-compartment, only the value of the table associated with the parent compartment is taken into account.
A block associated with a multi-tab must contain the multi-tab axis.
An empty field (NULL) in the data block will be interpreted as an absence of customisation: the data deposited in the questionnaire for this field/component will be the data defined during design.
It is advisable not to set a default value for components during questionnaire design. The exception is the non-customisable control containing a formula, this control being built with the gtcontrol function.