

La solution Gathering Tools est née d’une méthode que nous avons développée en observant le travail réellement effectué dans les organisations.
Dans cet article, nous détaillons les fondements de cette méthode ainsi que son implémentation au sein de la solution.
Les paradoxes d’Excel
C’est un paradoxe étonnant : alors que la liste des catastrophes provoquées par Excel ne cesse de s’allonger, Excel demeure la compétence technique la plus demandée au monde. Au nom de la lutte contre le Shadow IT, de nombreux DSI ont tenté de « tuer Excel » et, depuis près de 50 ans, des générations d’outils se sont présentées comme des « Excel Killer », depuis les « bases de données métier » type Paradox jusqu’aux solutions low-code. Et pourtant, Excel demeure un hyper-standard (plus de 90% du marché du tableur et plus d’un milliard d’utilisateurs mensuels). Pour ses détracteurs, Excel se comporte comme l’Hydre de Lerne : chaque fois qu’on lui coupe une tête, deux nouvelles têtes repoussent.
La thèse de cet article est qu’Excel n’est pas seulement un logiciel : c’est un support fondamental du travail réel et, pour de nombreuses organisations, une infrastructure de coordination et de mémoire. C’est la raison pour laquelle les tentatives de supprimer Excel échouent fréquemment : en supprimant le tableur, on supprime en même temps une grande partie de la valeur métier dont Excel était le réceptacle, créant ainsi une désorganisation opérationnelle alors même que le but était de structurer les processus.
Nous proposons une méthode différente, qui permet de combler les indiscutables lacunes techniques d’Excel tout en préservant le travail réel. En limitant la friction entre les utilisateurs et en réconciliant les objectifs des équipes techniques et des équipes fonctionnelles, notre méthode permet d’améliorer la qualité des données, de diminuer la charge de travail des équipes métier, de synchroniser les données avec le système d’information de l’organisation et de mettre en place une gouvernance qui assurera la pérennité du processus tout en conservant un haut niveau d’adoption par les utilisateurs.
Reconsidérer Excel : pas un outil, mais un artefact socio-technique
Excel en tant qu’objet-frontière et objet-mémoire
Une entreprise peut être vue comme un assemblage de compétences et de métiers interdépendants. Dans ce contexte, la création de valeur repose largement sur la capacité des acteurs à coordonner leurs activités et à collaborer efficacement, cette coordination constituant une dimension essentielle — mais souvent invisible — du travail réel. Cependant, d’un point de vue opérationnel, cette collaboration ne va pas de soi car les activités de l’organisation font intervenir des personnes dont les objectifs peuvent être très différents. Ainsi, les financiers, les commerciaux, les informaticiens et les gens des ressources humaines – pour ne prendre que quelques exemples – partagent évidemment les grands objectifs de leur organisation : ils souhaitent tous qu’elle prospère et qu’une partie de la valeur ainsi créée leur revienne. Mais individuellement, leurs objectifs diffèrent et cela est d’ailleurs facile à vérifier : il suffit de consulter les indicateurs sur lesquels sont calculés leur rémunération variable. La collaboration suppose donc un travail d’articulation entre l’objectif commun aux différents participants et leurs objectifs individuels respectifs.
Une grande partie de la collaboration se traduisant par des échanges d’informations, les supports de ces échanges jouent un rôle-clé dans la qualité de la collaboration. Dans la plupart des cas observés par la recherche, les acteurs d’un projet vont rapidement mettre en place ces supports d’échanges. Dans le champ de recherche du travail collaboratif assisté par ordinateurs (CSCW), ces supports sont dénommés « objets-frontières ». Les objets-frontières peuvent théoriquement être de tout type et de toute nature, mais ils possèdent généralement deux propriétés essentielles :
- Ils sont suffisamment structurés pour permettre la compréhension de l’objectif général de la collaboration
- Et suffisamment souples pour permettre une adaptation locale, ce fameux travail d’articulation.
Ces supports d’échange jouent également un autre rôle : ils permettent de conserver la trace des décisions prises, des arbitrages et des contextes. Cet historique informel est important car il permet à l’organisation de devenir apprenante, en tirant parti des décisions passées pour éclairer les arbitrages futurs. C’est pourquoi ces supports sont également souvent nommés « objets-mémoires ».
L’une de nos hypothèses est que si Excel est si universellement utilisé, c’est justement parce qu’il remplit bien ces 2 rôles.
- En tant qu’objet-frontière, Excel n’impose qu’une structure minimale (onglets, lignes et colonnes, typage minimal), il peut recevoir une grande richesse de contenu (texte, valeurs, formules, images, hyperliens, code VBA ou Python…), il peut être facilement partagé (notamment depuis les versions Office 365) et chaque utilisateur peut facilement ajouter son propre contenu ou faire une copie d’une fichier qu’il pourra « lier » au fichier source grâce à la syntaxe des formules de calcul qui autorise les dépendances externes.
- En tant qu’objet-mémoire, Excel supporte de nombreux mécanismes d’historisation : depuis la traçabilité structurée (chaque évènement étant matérialisé par un groupe de lignes, de colonnes ou d’onglets), jusqu’aux fonctions de commentaires qui permettent de documenter, cellule par cellule, les décisions prises. Enfin, si les premières versions d’Excel nécessitaient un archivage manuel, l’intégration avec SharePoint autorise la sauvegarde automatique et un versioning intelligent.
Encore une fois, Excel est loin d’être le seul outil logiciel pouvant servir d’objet-frontière : les outils de type Kanban (Jira, Trello…) ou les « tableaux blancs » sont également très utilisés. Mais Excel se révèle particulièrement efficace pour échanger des données numériques (valeurs, indicateurs, calculs, données d’historique…). De ce fait, l’utilisation dominante d’Excel nous semble traduire la dominance des dynamiques financières dans les organisations, et l’importance moindre des informations qualitatives.
De plus, Excel permet facilement de mettre en place des règles (notamment via les mises en forme conditionnelles) qui permettent de structurer le projet et de matérialiser certaines conventions implicites.
Enfin, il est certain que la position d’hyper-standard de cet outil contribue à son utilisation : Excel constitue une sorte d’acquis culturel, que chaque employé sait utiliser, même sans avoir reçu de formation formelle. Le succès d’Excel est ainsi auto-alimenté : sa versatilité et le fait que chaque employé sache l’utiliser contribue à le choisir comme artefact collaboratif. Et plus il est choisi, plus il est utilisé.
Pour autant, cela ne doit pas empêcher de considérer objectivement ses fragilités techniques.
En réalité, Excel ne s’impose pas malgré ses limites, mais précisément parce qu’il répond — de manière imparfaite mais pragmatique — aux exigences du travail réel.
Toutes ces raisons montrent le danger d’une approche consistant à « repartir d’une feuille blanche » : cela revient en effet à détruire le travail d’articulation accumulé, la mémoire des arbitrages, des exceptions, et tout le patrimoine collaboratif patiemment élaboré.
L’illusion du « simple remplacement technique »
Si la liberté qu’autorise Excel est justement ce qui lui permet d’être si efficace dans son rôle d’objet-frontière, elle est fréquemment vue comme une lacune par les dirigeants. D’un point de vue strictement technique, on ne peut pas leur donner tort : l’absence de contraintes peut effectivement engendrer des problèmes de qualité de données et surtout, les données manipulées dans Excel n’ont, au mieux, qu’un lien assez lâche avec le système d’information de l’organisation, ce qui peut poser des problèmes de synchronisation : il existe potentiellement « plusieurs versions de la vérité ».
Pour le dire autrement :
De nombreux dirigeants envisagent Excel comme une interface défaillante pour les données structurées.
Cette analyse n’est pas fausse, mais elle est incomplète.
La plupart des organisations pensent en effet disposer d’un système d’information cohérent, dont les briques de bases sont souvent similaires (ERP, CRM, SCM, BI…). Pour les dirigeants, la présence de ce système offre une impression de sécurité qui peut être trompeuse.
En effet, quelle proportion des données qui alimentent ces outils proviennent d’imports Excel issus de processus informels ? Et de même, quelle proportion des données de ces outils sont exportées vers Excel pour alimenter des processus informels ? Ces proportions sont rarement mesurées — et pour cause : les mesurer reviendrait souvent à révéler que le système d’information « officiel » ne reflète qu’une partie du travail réel. Mais elles dessinent en creux l’importance d’Excel qui, loin de se limiter à une utilisation purement locale, se révèle être une véritable infrastructure de coordination, à l’échelle de l’organisation tout entière.
Lorsqu’ils prennent conscience de l’importance d’Excel au sein de leur organisation, les dirigeants sont souvent tiraillés entre les deux seules options qu’ils pensent avoir à leur disposition :
- Minimiser le rôle d’Excel en arguant que les véritables décisions sont prises sur la base des données issues des outils du système d’information,
- Se lancer dans une croisade anti-Excel, en traquant tous les processus informels pour les remplacer par de « véritables outils » au nom de la lutte contre le Shadow IT.
Ces options nous semblent toutes deux inefficaces.
Car même si les dirigeants prennent effectivement leurs décisions sur la seule base des outils « officiels », que valent ces décisions si ces outils sont alimentés en partie par des imports Excel ? De plus, les organisations ne se développent pas uniquement par les décisions des dirigeants, mais également par tous les processus métiers dont, on l’a vu, une partie est outillée avec Excel.
La même logique, qui considère qu’Excel n’est qu’une interface défaillante, pousse justement les dirigeants à vouloir ré-outiller ces processus, en remplaçant Excel par un outil plus « structuré ». Or, nous observons que la plupart des tentatives échouent : au mieux, le « nouvel outil » est rejeté par les utilisateurs. Mais dans de nombreux cas, l’outil est imposé et les utilisateurs s’en servent… Tout en recréant un processus informel sans en avertir leurs managers. La lutte contre le Shadow IT aboutit alors à créer davantage de Shadow IT, et l’investissement consenti dans la mise en place du « nouvel outil » sera probablement peu rentabilisé, les données réelles continuant à être travaillées parallèlement dans Excel.
L’échec de ces tentatives nous semble dû à 2 causes principales.
-
La structuration précoce
Dans une optique très « darwinienne », les processus informels naissent spontanément. En permanence, des utilisateurs en sollicitent d’autres afin d’accomplir leurs missions. Ces sollicitations ne donneront pas toujours naissance à un processus pérenne, mais le point à retenir est que les processus collaboratifs informels ne sont pas toujours la conséquence d’une demande du management : c’est d’ailleurs l’une des raisons pour lesquels ils sont peu visibles.
Nous avons observé que la mise en place de la collaboration comporte toujours deux phases distinctes.
- Une phase d’exploration, au cours de laquelle les participants vont confronter leurs visions du projet et négocier le contour du processus. C’est une phase de tâtonnements, d’essais/erreurs et de négociations durant laquelle s’élabore la forme primitive des documents qui soutiendront la collaboration. Durant cette phase, la « mortalité » des processus est importante : les acteurs peuvent parvenir à la conclusion que les conditions de la collaboration telle qu’initialement imaginée ne sont pas réunies, et le projet en restera là. Mais s’il survit, les documents qui soutiendront la collaboration auront connu de nombreuses itérations, avec parfois des modifications radicales d’une version à une autre.
- Une phase de stabilisation, au cours de laquelle la collaboration devient effectivement un processus. Plusieurs signes permettent de détecter cette phase :
- Le document est réutilisé et plusieurs acteurs y contribuent régulièrement
- Les utilisateurs prennent conscience que les erreurs sont coûteuses
- En réponse, ils commencent à expliciter de premières règles.
L’une des raisons pour lesquelles la volonté d’outiller un processus informel en remplacement d’Excel échoue tient justement à ce phasage. En effet, la plupart des outils « officiels » nécessiteront de commencer l’implémentation par la création d’un modèle de données. Le problème est que :
- Si le processus est en phase d’exploration, vouloir imposer un modèle de données reviendra à figer un processus qui est encore phase d’élaboration. Dans ces conditions, il existe un risque important que le modèle de données ne corresponde pas au processus une fois stabilisé.
- Si le processus est en phase de stabilisation, les documents collaboratifs ont déjà été créés et validés par les utilisateurs puisque ces documents matérialisent leurs arbitrages. A ce stade, la plus-value d’un outil qui viendrait remplacer ces documents risque de ne pas apparaître aux yeux des utilisateurs, qui verront surtout que les documents qu’ils ont patiemment construits seront supprimés par le nouvel outil.
Autrement dit :
Plus un outil formalise tôt, plus il risque d’être rejeté, mais plus il formalise tard, moins il est utile.
Ce qui nous emmène au second point :
-
La tentation de la « table rase »
Les classeurs Excel issus de la collaboration des experts métiers peuvent être d’une grande complexité, et les processus par lesquels ces documents sont échangés, enrichis et exploités peuvent entrainer une charge de travail importante. Cette complexité va mettre en lumière un certain nombre de lacunes techniques inhérentes à Excel. Pour mieux les appréhender, nous pouvons considérer qu’un processus collaboratif basé sur Excel comporte généralement 4 phases :
- Préparation des documents. Les processus métiers sont situés dans le temps et dans l’espace de l’organisation. La dimension temporelle est incarnée par la fréquence du processus (tous les mois, années, trimestres…) et chaque indicateur du document se rapporte à une période de temps définie. Souvent, les documents illustrent les évolutions d’une période à une autre. La dimension spatiale de l’organisation détermine les périmètres d’intervention des participants au processus. Cette organisation peut être géographique (pays, région…) ou structurelle (Business Unit, métier, projet…). Afin que chaque participant au projet puisse accéder et enrichir les données de son périmètre, il sera nécessaire de matérialiser ces périmètres dans l’espace des documents. Ainsi, chaque périmètre pourra donner lieu à un document à un onglet ou à un tableau distinct. La préparation des documents implique donc potentiellement, à chaque période, de mettre à jour de nombreux documents afin de tenir compte de la nouvelle période (actualisation) et des éventuelles modifications de périmètres intervenues entretemps. Cette mise à jour peut représenter une charge de travail importante si elle n’est pas automatisée. Et si elle l’est dans Excel, c’est fréquemment à l’aide code type VBA et Python. Or, l’intégration de code dans Excel est susceptible d’engendrer des problèmes de sécurité et surtout, la compétence de développement est inégalement répandue chez les utilisateurs métiers. Le risque est alors la mise en place d’une dépendance à des personnes spécifiques.
- Fourniture des données. Une fois les documents mis à jour, la collaboration proprement dite va pouvoir se mettre en place. Cette collaboration implique un enrichissement des documents, chaque utilisateur ayant la charge de fournir les données actualisées pour le périmètre qui lui est affecté. Lors de cette phase, le principal risque est d’obtenir une faible qualité des données. Excel, en effet, n’est pas un outil de formulaires et ne propose pas de mécanismes proprement transactionnels. De ce fait, il est malaisé d’empêcher un utilisateur de fournir un jeu de données incomplet. De même, Excel propose des fonctionnalités de validation des données qui permettent d’imposer, pour une cellule des données, un type de données et des contraintes spécifiques mais ces fonctionnalités peuvent être facilement contournées. Surtout nous avons observé que plus les concepteurs de documents « verrouillaient » les fichiers Excel (notamment à l’aide des fonctionnalités de « protection »), moins les utilisateurs s’impliquaient dans le processus. En effet, les efforts pour figer le document empêchent concrètement l’adaptation locale, dont nous avons vu qu’elle est une des conditions de la collaboration.
- Workflow. Excel ne proposant pas directement de fonctionnalités transactionnelles, le suivi de la complétude des périmètres est généralement réalisé manuellement (« pointage » des périmètres complétés, relances des non-répondants…). De plus, les organisations sont souvent désireuses de mettre en place des étapes de validation (par exemple, les données fournies par un employé devront être validées par son manager avant de pouvoir être prises en compte dans le processus). Là encore, Excel ne propose pas de fonctionnalités de Workflow et ces échanges sont matérialisés dans les documents (avec des zones dédiées) soit dans des échanges (par mail, par versionning de fichier), et ces pratiques sont fragiles quant aux erreurs manuelles.
- Synthèse. Une fois les données fournies, complétées et validées, elles doivent être rassemblées afin de pouvoir être exploitées. L’absence de structure imposée par Excel, qui fait sa force lors de la phase d’exploration, est ici un désavantage objectif : rassembler les valeurs issues d’un grand nombre de cellules disséminées dans des tableaux, feuilles et documents différents est un travail ardu. C’est également un travail fragile : l’adressage des valeurs étant réalisé sous forme de coordonnées lignes/colonnes, le moindre décalage lors des phases précédentes générera des erreurs, qui peuvent être longues à identifier.
La charge globale du processus est objectivement importante. Mais sa perception est fréquemment renforcée par deux facteurs qui tiennent à l’image d’accessibilité inhérente à Excel :
- Puisqu’Excel est d’abord perçu comme un outil local, il apparait inadéquat pour implémenter un processus collaboratif récurrent.
- Puisque la plupart des utilisateurs d’Excel sont autodidactes, Excel est perçu comme un outil simple et dès lors, il semble inapproprié de l’utiliser pour des processus complexes.
Dès lors, si Excel apparait comme inadéquat, il semble logique de le remplacer par un autre outil. Le risque est qu’avec la disparition des fichiers Excel disparaitront également une grande partie de spécifications du projet : structures, règles, traces des décisions et toutes les connaissances implicites accumulées lors des phases d’exploration et de stabilisation.
Il est évidemment possible de lancer une phase de spécifications pour créer et paramétrer le nouvel outil mais en pratique, cela reviendra à assumer le coût d’une seconde phase d’exploration sans plus pouvoir bénéficier d’Excel pour articuler les perspectives des différents acteurs. Ce même problème se posera à chaque évolution du process.
De plus, le nouvel outil nécessitera une formation pour les utilisateurs.
Enfin, lorsque le nouvel outil sera en place, s’il ne permet pas l’adaptation locale, il risque d’ajouter une surcharge cognitive importante pour les utilisateurs, augmentant le risque d’un rejet ou de contournement… Et la recréation d’un processus Excel officieux.
Ainsi, il apparait clairement que si les outils officiels échouent à remplacer Excel, cela n’est pas dû à une mauvaise conception technique, mais au fait qu’ils ignorent la dynamique de formation des processus. Le succès d’Excel réside précisément dans sa capacité à accompagner cette dynamique. Pour autant, dans le cadre d’une utilisation en production, ses lacunes techniques sont objectivement problématiques. Comment les combler tout en préservant la capacité à épouser les dynamiques de collaboration ? C’est ce que nous allons à présent détailler.
Notre méthode pour remplacer Excel sans perdre la logique métier
Notre méthode repose sur 6 étapes. Son but est de capitaliser sur le travail fourni par les opérateurs de la collaboration lors des phases d’exploration et de stabilisation, en acceptant le fait que les différentes expertises métier et les arbitrages nécessaires à la collaboration des différentes expertises métier y ont déjà été rendus.
De ce fait, nous accorderons une place centrale aux classeurs Excel élaborés à l’issue de ces phases, qui seront considérés comme la spécification principale du projet. Cela permettra à la fois :
- De proposer une implémentation respectueuse de l’expertise métier tout en limitant la friction et la surcharge cognitive qui seraient ajoutés par un « nouvel outil ».
- De permettre une passerelle la plus fluide possible entre la spécification et l’implémentation, facilitant ainsi les évolutions naturelles du processus.
1. Capturer le réel
Le travail réel ne se réduit pas à ses artefacts : il implique également des transactions, des échanges entre acteurs sur les différents périmètres du processus.
Techniquement, le projet peut donc être résumé à 2 types d’objets :
- Des documents (qui serviront à la fourniture, la validation et la synthèse des données échangées au cours du processus)
- Des transactions, au cours desquelles les acteurs se voient affecter des tâches sur des périmètres, à réaliser dans un ordre précis. Ces transactions sont parfois informelles, parfois formalisées également dans Excel ou dans tout autre outil. Dans le cadre de la phase de stabilisation, il est important d’encourager les utilisateurs à formaliser ces transactions, de préférence dans un autre fichier Excel. En effet, cela leur permettra à nouveau de préciser leurs arbitrages et cela aura pour effet de faciliter la structuration des données relatives aux transactions, ce qui simplifiera l’implémentation et harmonisera le processus global.
A ce stade, nous nous trouvons avec 3 types de documents Excel :
- Les documents qui serviront au recueil de données, que nous nommerons « questionnaires ». Un point important est de séparer les documents partagés, qui servent à la collaboration globale, de leurs variantes locales, et de comprendre en quoi leurs structures diffèrent.
- Les documents qui serviront à la synthèse des données, que nous nommerons « restitutions »
- Un document décrivant les transactions, que nous nommerons « questionnaire de paramétrage »
2. Préserver l’apparence et les fonctionnalités
Une fois ces documents rassemblés il reste à les transformer en interface. Plus l’apparence et les fonctionnalités seront proches des documents Excel rassemblés, plus faible sera la surcharge cognitive pour les utilisateurs.
3. Extraire et formaliser les règles
Les règles sont l’une des sources de la qualité de données. Ici, elles doivent empêcher les utilisateurs de fournir un jeu de données incomplet ou incohérent. Au niveau d’un document, il existe plusieurs niveaux de granularité des règles, dont chacune obéit à une gestion particulière :
- Règles locales à une cellule : types et listes de données, bornes, obligatoire ou non… En cas de violation, il est possible d’invalider la donnée fournie dans la cellule.
- Impliquer plusieurs cellules : comparaison de cellules et de formules entre elles. Lors de la transmission des données, il sera possible de vérifier les règles et de bloquer la transmission en indiquant les dépendances impliquées.
- Globales au document : définir quelles sont les actions possibles pour un périmètre donné (ajouter ou supprimer des enregistrements / lignes / colonnes / feuilles, gestion de l’unicité). Lors de l’ajout ou de la suppression d’enregistrement, il sera possible d’invalider l’opération.
Suivant la complexité des règles et les compétences Excel des utilisateurs, il est possible que les modèles Excel implémentent déjà un certain nombre de règles en utilisant les fonctionnalités dédiées d’Excel : validation des données, mises en forme conditionnelles, macros, etc. Dans la mesure du possible, les règles déjà implémentées doivent être conservées et amplifiées : par exemple, en ajoutant pour chaque règle, des messages explicatifs ainsi que la possibilité d’afficher les dépendances affectées.
4. Structurer sans modifier l’apparence
Les données issues d’Excel échappent souvent au système d’information en raison d’un malentendu structurel : elles sont assimilées à des données structurées, alors qu’elles ne respectent aucun schéma explicite ni contraint. Leur intégration dans des data lakes ne résout pas ce problème : stockés sous forme d’objets, les fichiers Excel ne deviennent pas pour autant exploitables analytiquement, faute de modélisation et de normalisation préalables.
Or, notre hypothèse est que les classeurs Excel contiennent en réalité des structures, mais que ces structures sont uniquement visuelles. Notre méthode prévoit donc de les formaliser explicitement afin de pouvoir les synchroniser avec toute base de données relationnelle.
Notre première étape de structuration consiste à identifier les cellules dont la valeur sera intégrée dans le jeu de données créé lors de la transmission de la réponse.
La deuxième étape, consiste à distribuer ces valeurs dans des structures qui correspondent aux structures visuelles créées par les utilisateurs tout en facilitant leur exploitation. Ce faisant, nous créerons implicitement un modèle de données.
Nous distinguons 3 types de structures :
- Les motifs, qui sont similaires à des tables en ce qu’ils contiennent des enregistrements, mais qui sont des plages de cellules qui se comportent comme des enregistrements : par exemple, l’utilisateur peut être autorisé à ajouter des enregistrements, ce qui répliquera la plage entière et toutes ses propriétés. La gestion de ces plages par enregistrement permet de réaliser des traitements qui ne sont pas directement disponibles dans Excel. Par exemple, en définissant une liste de cellules dont la combinaison définit une « clé primaire », il devient possible de gérer l’unicité des enregistrements.
- Les dimensions croisées, qui définissent chaque cellule incorporée dans le jeu de données comme étant au croisement d’un certain nombre de dimensions (date, indicateur, et autres dimensions métier).
- Enfin, certaines données seront globales au document, et automatiquement intégrées dans une structure unique, agissant comme la « racine » des données. Notre hypothèse est que toute donnée n’appartenant ni à un pattern, ni à un croisement de dimensions sera automatiquement affectée à la racine.
Voici un exemple de motif :
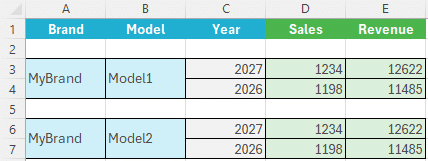
La plage de cellules à répliquer correspond à A2 :E4
La clé primaire est définie par la combinaison des cellules A3 et B3
Ici, l’utilisateur a créé 2 enregistrements : MyBrand \ Model1 et MyBrand \ Model2. Si l’utilisateur avait saisi « Model1 » dans la cellule B6, l’ajout de l’enregistrement aurait soulevé une exception de violation d’unicité.
Voici la structure de données exposée par le motif pour synchronisation :
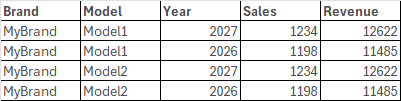
Voici maintenant un exemple de structure à dimensions croisées :
![]()
Ici, chaque valeur correspond au croisement d’un indicateur « Sales » ou « Revenue » et d’une des 3 dimensions exposées (Brand, Model, Year)
Une fois les dimensions identifiées, il est possible de les distribuer afin de créer une structure de données correspondant au besoin.
Voici un exemple de structure de données pouvant être réalisée à partir de cet exemple :
![]()
En combinant ces 2 structures, il devient possible de créer, au sein des documents, des jeux de données tabulaires regroupant toutes les valeurs pertinentes sans modifier la mise en forme. Cette « structuration invisible » illustre le but de notre méthode : préserver les documents métiers tout en fiabilisant le processus au sein du système d’information.
5. Intégrer au système d’information
Une fois les structures du document définies, elles peuvent être synchronisées à n’importe quelle base de données relationnelle et, de ce fait, être disponibles pour n’importe quel outil via une connexion base de données ou une API.
Grace à cette synchronisation, il sera possible de garantir que chaque utilisateur :
- Bénéficiera des données les plus récentes lors de la manipulation d’un document
- Contribuera activement à l’enrichissement du système d’information, chaque donnée modifiée dans le document étant automatiquement disponible pour le SI.
Cette synchronisation au SI remplacera efficacement les « liaisons » Excel qui sont fragiles et qui adressent les données cellule par cellule alors que la synchronisation fonctionne structure par structure, offrant ainsi de meilleures performances et une maintenance facilitée.
6. Combiner gouvernance et adaptation locale
Notre méthode permet donc :
- De convertir les documents issus de la collaboration des utilisateurs en formulaires permettant d’enrichir le système d’information. Dans le cadre d’une campagne de collecte, ces documents seront considérés comme des « modèles de formulaires ».
- De faire en sorte que pour chaque périmètre fonctionnel, un document dérivé de l’un des modèles soit mis à disposition des utilisateurs affectés, et automatiquement pré-rempli des données correspondant à son périmètre.
- De garantir la qualité des données fournies par les utilisateurs grâce aux règles définies en central.
Mais elle permet également de gérer efficacement l’adaptation locale, dont la recherche a montré qu’elle est l’une des conditions de la collaboration. A cet effet, nous proposons que chaque utilisateur qui se voit affecter un document à enrichir puisse exporter ce document au format Excel. Ce faisant, il retrouvera un document qu’il sera libre d’enrichir et de modifier en fonction de ses besoins locaux. Ensuite, les données de ce document seront réimportées dans le formulaire. Ainsi, les possibilités d’adaptation locale sont quasi-infinies. Le risque de cette approche serait évidemment de retrouver les fragilités inhérentes à Excel en matière de qualité de données. Mais nous proposons de limiter ces risques de 2 façons :
- Lors de la génération de l’export Exel, chaque cellule correspondant à une donnée collectée se verra attribuer un identifiant unique, et cet identifiant sera apposé en tant que « zone nommée » sur la cellule Excel. Ainsi, même si l’utilisateur ajoute des lignes et /ou des colonnes dans le classeur Exporté, lors de l’import, les données seront importées par leur identifiant et non par leur position.
- De plus, si l’utilisateur bénéficie d’une grande liberté lors de l’enrichissement de son export Excel, toutes les règles de gestion seront activées lors de l’import des données locales dans le formulaire, ce dernier étant le garant de la qualité des données.
Bénéfices-clé : combiner flexibilité et contrôle
En résumé, notre méthode permet d’aligner les objectifs de l’ensemble des acteurs de l’organisation :
- Pour les utilisateurs fonctionnels, elle limite la surcharge cognitive en réutilisant le matériel de collaboration qu’ils ont eux-mêmes construits. De plus, lorsque les utilisateurs désireront faire évoluer le processus, ils n’auront qu’à faire évoluer les documents Excel et il sera aisé de mettre à jour les modifications dans le projet implémenté.
- Pour le management, notre méthode permet de garantir la qualité des données tout en valorisant l’expertise des utilisateurs fonctionnels.
- Pour la DSI, elle « extrait » les données Excel du shadow IT et participe pleinement à l’enrichissement du SI tout en assurant le principe d’ « une version unique de la vérité »
- Enfin, pour les utilisateurs en charge de l’enrichissement des données, elle permet l’adaptation locale tout en préservant la qualité globale des données.
Pour conclure, là où les approches classiques cherchent à remplacer Excel, notre méthode consiste à le considérer comme la source de vérité du métier — puis à en extraire une structure exploitable par le système d’information.